谷歌浏览器下载断线续传原理及应用实例

一、断线续传原理
1. 数据分块与记录:
- 当在Chrome浏览器中开始下载文件时,浏览器会将文件分成多个小块进行下载。同时,它会记录每个已下载小块的信息,包括其在文件中的位置和数据内容。这些信息会被存储在本地的临时文件夹中,通常位于系统的缓存目录下。例如,在Windows系统中,这个临时文件夹可能是“C:\Users\[用户名]\AppData\Local\Google\Chrome\User Data\Default\Cache”目录;在Mac系统中,也有相应的缓存目录来存储这些信息。
2. 断线检测与恢复准备:
- 如果在下载过程中网络连接中断,Chrome浏览器会自动检测到这种情况。当网络重新连接后,浏览器会读取之前记录的已下载小块信息。它会根据这些信息,向服务器发送请求,告知服务器需要从上次中断的地方继续下载。服务器会根据请求,从上次中断的位置开始继续传输文件的剩余部分。
3. 校验与合并:
- 在续传过程中,Chrome浏览器会对新下载的数据块进行校验,确保数据的完整性和准确性。这通常是通过计算数据的哈希值(如MD5、SHA - 1等)并与之前记录的值进行对比来实现的。如果校验通过,浏览器会将新下载的数据块与之前已下载的数据块按照正确的顺序进行合并,最终形成完整的文件。如果校验不通过,浏览器可能会重新下载该数据块,以确保文件的正确性。
二、应用实例
1. 下载大文件时的断线续传:
- 例如,在下载一个大型的视频文件或软件安装包时,可能会遇到网络不稳定导致下载中断的情况。当网络恢复后,Chrome浏览器会自动尝试从上次中断的地方继续下载。用户无需重新点击下载链接,浏览器会自动处理续传过程。在下载过程中,用户可以通过查看下载进度条来了解下载的进展情况。如果下载再次中断,浏览器会继续记录已下载的部分,等待网络恢复后继续下载,直到文件完整下载到本地。
2. 利用断线续传功能优化下载策略:
- 对于一些需要定期更新的大型文件,如系统更新补丁、大型游戏更新文件等,可以利用Chrome浏览器的断线续传功能来优化下载策略。用户可以在网络状况良好的时候开始下载,如果遇到网络问题导致下载中断,不用担心文件需要重新下载。当网络恢复后,浏览器会自动继续下载,这样可以节省下载时间和流量。同时,用户还可以结合浏览器的任务计划功能(如果有),设置在特定的时间自动开始下载任务,充分利用网络空闲时段进行下载,提高下载效率。

如何清理QQ浏览器电脑版缓存
如何清理QQ浏览器电脑版缓存?大家是否和小编一样,电脑中的QQ浏览器用着用着,就会出现越来越卡顿的现象?甚至有时出现视频画面停住不动,但声音却仍在播放的情况。

Chrome浏览器如何添加多个账户配置
Chrome浏览器支持添加多个账户,用户可快速切换不同配置,便于多用户共享设备或分开管理工作和生活账号。

傲游云浏览器速度快不快
傲游浏览器采用了傲游自主研发的全球首款双核引擎,具备高效的浏览速度及稳定性,使浏览网页更加流畅。

Chrome浏览器插件下载及安装全指南
Chrome浏览器插件可扩展功能范围,提升使用体验。教程涵盖插件查找、下载、安装与管理全流程,帮助用户高效完成操作。

google Chrome浏览器多标签分组管理技巧及应用教程
分享google Chrome浏览器多标签分组的管理技巧和实际应用方法,帮助用户高效整理标签页,提升浏览体验和工作效率。

chrome浏览器如何配置代理设置进行匿名浏览
通过配置代理设置,Chrome浏览器可以进行匿名浏览,提升用户的隐私保护。

如何修复谷歌浏览器更新检查失败错误代码3:0x80040154?
谷歌浏览器是世界上最受欢迎的浏览器之一,许多用户更喜欢将其作为Windows PC上的默认浏览器。Chrome提供了广泛的功能,使浏览体验变得愉快和容易。因此,它仍然是最值得信赖的浏览器之一。然而,就像任何其他浏览器一样,即使是Chrome也有自己的缺点,在你最需要的时候,它也同样容易出现错误和故障。

谷歌浏览器的下载教程及基础配置<基础下载教学>
你知道如何下载安装并配置谷歌浏览器吗?你想进入信息时代吗?快来一起学习谷歌浏览器最基础的技巧吧,专为新人制作!

如何设置谷歌浏览器的下载路径
如何设置谷歌浏览器的下载路径?接下来就让小编给大家带来谷歌浏览器设置下载路径方法技巧,感兴趣的朋友千万不要错过了。

谷歌浏览器个人资料发生错误怎么办
谷歌浏览器个人资料发生错误怎么办?接下来就让小编给大家带来谷歌浏览器个人资料错误问题方法技巧,感兴趣的朋友快来看看吧。

用谷歌浏览器自动跳转别的浏览器怎么办
用谷歌浏览器自动跳转别的浏览器怎么办?下面就让小编给大家带来解决谷歌浏览器自动跳转方法步骤,感兴趣的朋友千万不要错过了。
如何在 Ubuntu 20.04 上安装谷歌浏览器?
谷歌浏览器是众所周知的、快速且安全的网络浏览器。由于 google chrome 不是开源软件程序,这就是为什么您无法在 Ubuntu 的软件中心找到它的原因。您可以在那里找到 chromium 网络浏览器,但它不是原始的“Google Chrome”网络浏览器。
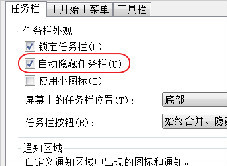
谷歌浏览器始终在最前端怎么回事_win7谷歌浏览器问题
谷歌浏览器始终在最前端怎么回事,还有其他软件也有这种问题?小编这就带你解决问题

谷歌浏览器如何将网页双面打印
谷歌浏览器如何将网页双面打印?本篇文章就给大家带来谷歌浏览器设置网页双面打印教程详解,需要的朋友赶紧来学习一下吧。
谷歌浏览器的英文界面改成中文
本网站提供谷歌官网正版谷歌浏览器【google chrome】下载安装包,软件经过安全检测,无捆绑,无广告,操作简单方便。

如何在谷歌浏览器中显示主页按钮?
本文介绍了如何显示Google Chrome网络浏览器的主页按钮,该按钮默认不显示,因为 Chrome 旨在呈现一个整洁的界面。

在Windows上清除Chrome的缓存和历史记录
要在Windows上清除Chrome的缓存和历史记录,请按照以下步骤操作。

谷歌浏览器flash插件怎么安装
谷歌浏览器flash插件怎么安装?接下来小编就给大家带来谷歌浏览器安装flash插件步骤一览,希望能够给大家带来帮助。





